RVC用のデータセットの作り方
はじめに
当方はPythonや機械学習初心者、PCに疎く専門知識も全くありません。
色々と間違っているかと思いますが、ご容赦いただけますと幸いです。
この記事に肖像権の侵害を助長する意図はございません。
個人で楽しむ範囲でのご利用をお願いします。
機械学習といえば高スペックを要求されるものだと考えがちですが、PCのスペックが低くても「GPUSOROBAN」という仮想サーバーサービスを利用してRVCを動かすことができます。
レンタル料がかかりますが、500円も行かない金額なのでPCを新調するよりお財布に優しいです。
その方法は後日ご紹介します。
ものすごく脳筋解説になりますので、私と同じく機械学習がよく分からない方、寛容な方のみお読みいただければと思います。
当方の使用PCは
と、あまり高くありませんが、データセット作りの時点では十分動いてくれていますので使用PCの目安にしてください。
RVCって?
RVCとは「Retrieval-based Voice Changer」の略で、AIによって声質変換を行うソフトウェアのことです。
好きな声を学習させることでその声に文章を読み上げさせたり、好きな曲を歌わせることができます。
RVCはスマホでできる?
気になる方が多そうなので初めに申し上げておきますが、RVCにスマホで挑戦するのは難しいと思います。
今年春頃まではスマホでも可能だったようですが、現在はGoogleColab無料版でWebUIが使用不可になったため、スマホではできないと思います。
有料版ならまだ使えるらしいですが、自身で試していないので詳細は不明です。
そもそも音声素材の準備にスマホが向いてないので、おすすめできません>﹏<
素材集めを頑張った割に出来が悪い、似てない…となる可能性が高いので、PCでの作業をおすすめします。
準備編
使用するもの
・低スペックでもちゃんと動くPC(HDDの空き容量は2〜30Gくらいあった方がいいかも?)
・Reaper(PCアプリケーション)などの音源編集ソフト
・ボーカル抽出ソフトやサービス
・根気
データセット作成の手順をざっくりまとめると
- 最低10分程度の音声データの収集(喋り声、歌どちらでも可)
- 音声データからBGMやエコーを取り除く加工処理
- 集めた音声を4〜10秒に切り分ける
- 分割した音声をwavファイルとして書き出す
この4工程になります。
RVCは学習と推論にはそれほど時間はかからないですが、音声データの収集と処理にかなりの時間を要します。
地味で面倒な作業ですが、手間をかけた方がクオリティが良くなるので頑張りましょう!
1.最低10分程度の音声データの収集
音声のデータを合わせて10分程度になるように集めます。
この時点ではサンプリングレートやファイル形式などは気にしなくて大丈夫です。
動画でもOK、喋り声と歌唱どちらも可能です。
歌わせたいのであれば歌唱音声を中心に、喋らせたいのであれば口語を中心に集めた方がいいかもしれません。
注意点
・量より質←最重要!!
・覚えさせたい声色を集める
・PCにGPUがない場合、コーラスやエコーの加工がついた歌は避ける
大事なのは量より質です!!
ガビガビの音声データ1000個よりもクリアな音声100個の方がクオリティが良くなるので、音質の悪いものは使わないようにしましょう。
ある程度の雑音やノイズは後で消せるのでそこまで気にしなくても大丈夫です!
少しくらいなら完成品にBGMとエコーつけたら大体誤魔化せます。
声色についても注意が必要です。
儚げな声で喋らせたいのに、ハキハキした音声ばかり集めたらAIは学習したハキハキした声しか出せません。
理想に近い声色を集めた方が良いです。
歌唱音声は後述するUVRを使えないPCスペックの場合、コーラスやエコーを取り除くことができないので、使える部分が少ないかもしれません…
後々学習モデルに変換させる音源も、コーラスとエコー除去した方がしっかり認識してくれます。
2.音声データからBGMやエコーを取り除く加工処理
集めた音声データからBGMや雑音を取り除いていきます。
私はUVRでBGMとエコー除去、ノイズはRX8のDe-noiseで処理しています。
UVRはGPU使わないとろくに使えないと思うので、お使いのPCにグラボがない場合はwebのボーカルリムーバーやMoisesを使うなどしてBGMを取り除きましょう。
ノイズ除去はReaperというアプリケーションにReaFirというプラグインを導入することで取り除くことができます。
Reaperはこの後の切り分け作業でも使用しますのでインストールしておきましょう。
UVRはボーカル抽出は勿論、エコーとコーラス除去も可能です。
また、動画でもmp4ファイルであれば音声を抽出してくれますので、動画ファイルをわざわざ音声ファイルに変換する手間もかかりません。
ただし.movは対応していませんでした。
ボーカル抽出→エコー除去→コーラス除去の順番で処理していきます。
初期状態では処理してくれるモデルがダウンロードされていないので、以下の名前のモデルをダウンロードします。
MDX-Net
・UVR-MDX-Net Main(ボーカル抽出)
・UVR-MDX-Net Karaoke(コーラス除去)
VR Architecture
・UVR-De-Echo-Normal(エコー除去)
・5_HP-Karaoke-UVR(コーラス除去)
UVRの詳しい導入方法はこちらの記事を参考にしてください。
UVRでの作業工程
UVR-MDX-Net Main(ボーカル抽出)
↓
UVR-De-Echo-Normal(エコー除去)
↓
UVR-MDX-Net Karaoke(コーラス除去 弱い)
もしくは
5_HP-Karaoke-UVR(コーラス除去 強い)
「5_HP-Karaoke-UVR」の方が強力でオクターブ下のコーラスも綺麗に消してくれますが、たまにメインボーカルまで削ってしまうので好みで使い分けてください。
3.集めた音声を4〜10秒に切り分ける
Reaperを使用して切り分けていきます。
Reaperでなくとも、音声ファイルをカットしてまとめてレンダリングできるアプリならなんでもOKですので、使いやすいアプリを使用してください。
Reaperはデフォルト言語が英語になっているので、まずは日本語化しましょう。
導入方法と日本語化の方法は以下の記事を参考にしてください。
ノイズ除去をしていきます。
私は昔購入したRX8のDe-noiseが勝手に認識されてたので(なぜかは分からない…)それを使って音声を綺麗にしています。
RX8のDe-noiseを購入せずとも、Reaperのプラグイン「ReaFir」を使用すれば十分ノイズを消してくれると思います。
ReaFirの導入方法と使い方はこちらの記事を参考にしてください。
上記の記事を参考にインストールが完了しましたら、音声ファイルの無音部分を読み込ませてノイズを消します。
この時、声の部分を読み込ませると声が消えてしまいますのでご注意ください!
一通り終えたら次は音声ファイルを発語ごとに切っていきます。

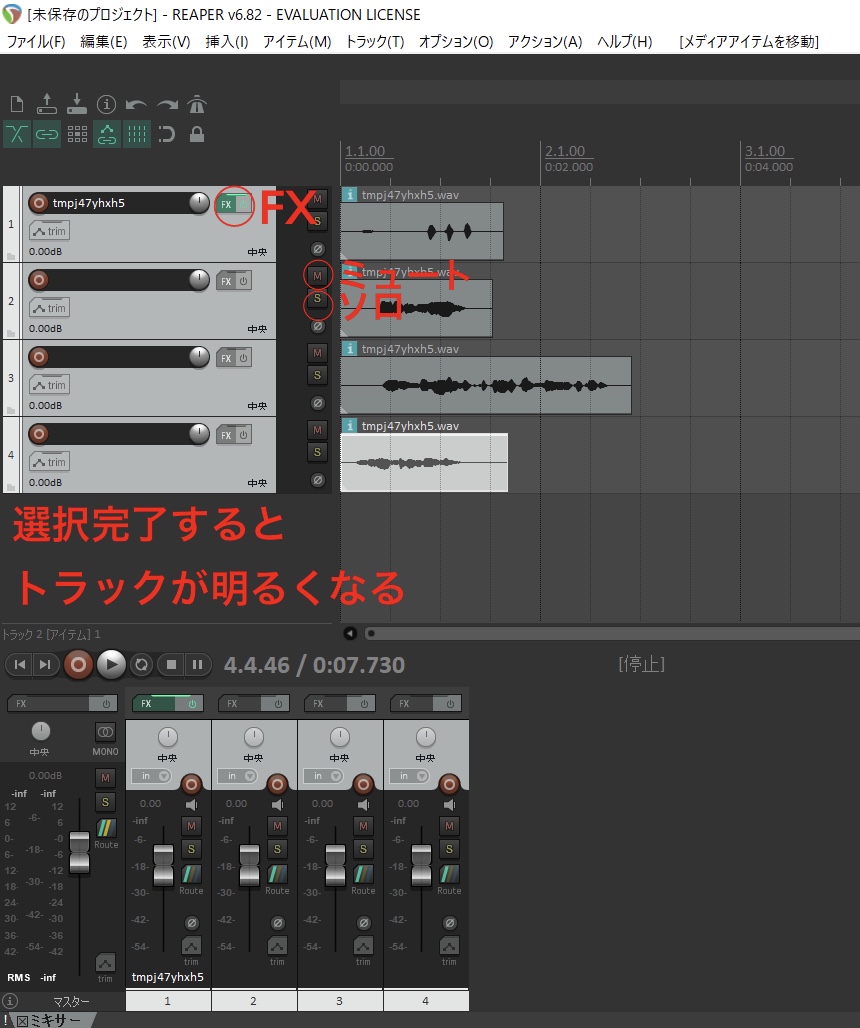
初期だとスナップが有効になっていて細かく動かせないので、磁石マークもしくは[Alt+S]でスナップを無効にします。
[S]を押すと、青いカーソルがある位置で音声がカットされます。
カットした音声を下にドラッグして、発語ごとにトラックを追加していきます。
この時ノイズ処理のエフェクトがかかっているのは一番上のトラックだけになりますので、FXを下のトラックのFXにドラッグしてエフェクトをコピーしてください。
赤いMマークをクリックするとそのトラックがミュートに、黄色のSマークをクリックするとそのトラックのみがソロ再生されます。
4〜10秒に切り分けるのが良いとの情報を見かけましたが、RVCに読み込ませたファイルを見るとAIが2、3秒でぶつ切りに処理しているので下限は気にしなくても大丈夫そうな気がしています。
10分ぶんあれば大体ファイル数は100は超えると思います。
2~3秒の音声ファイルを繋げて10秒にまとめて、60個のファイルのデータセットで学習させた時は出来がとても悪かったです。
平均5秒くらいのファイルを200〜300個集めてやっと満足できるクオリティになったと感じています。
4.分割した音声をwavファイルとして書き出す
トラックの上で[Ctrl+A]で全トラックの選択後「ファイル」タブから「音声ファイルにレンダリング」をクリック

対象のプルダウンメニューから「Selected Tracks(stems)」を選択
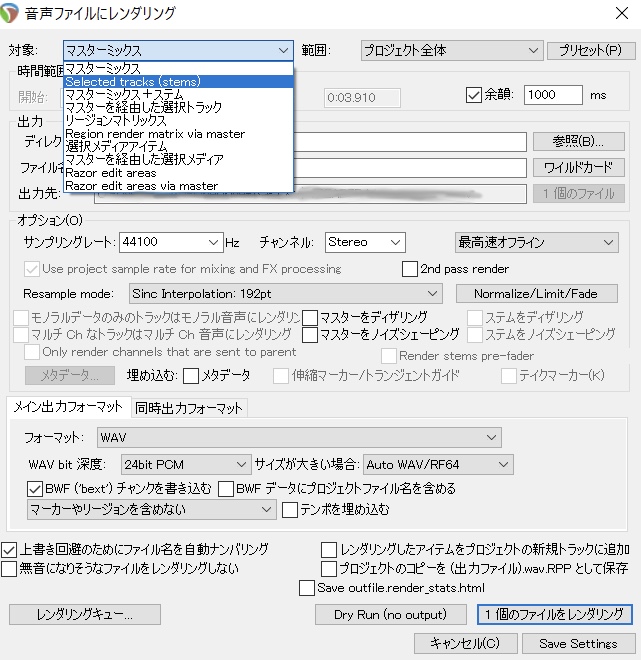
参照ボタンをクリックして保存先のフォルダを指定(画像ではEドライブ/Voiceの中に”声”というフォルダを作ってそこを指定しています。)
ファイル名を入力(testにしてあります。)
ファイル名はRVCに読み込ませた時にエラーが発生する可能性があるので、日本語を使わないようにしましょう。
現在は日本語名でも大丈夫なように修正されたらしいですが、英語で名付けておいた方が無難です。
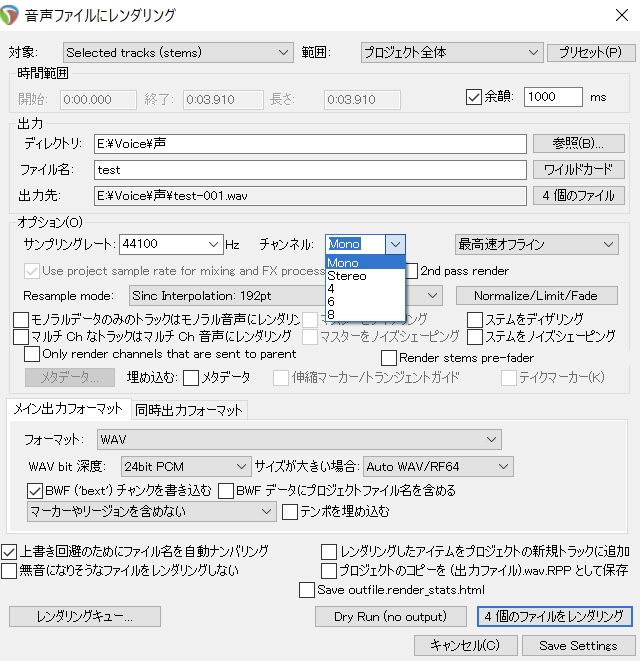
次は
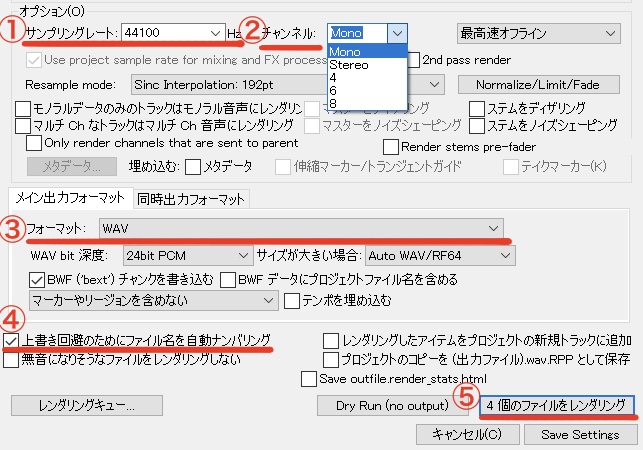
サンプリングレート「44100Hz」※
チャンネル「Mono(モノラル)」
フォーマット「wav」
の設定を確認します。
※サンプリングレートについて
RVCv1は40・48kHz、v2は36・44・48kHzに対応しています。
48kHzの方が音質がいいみたいですが、Windowsの音声設定や機材周りも変更しなければいけないらしく(デフォルト設定では44.1kHzになっていると思うので)
ノイズが出るという情報も見かけましたので私は44.1kHzを選んでいます。
44.1kHzと48kHzの違いを聞き分けられるほど耳良くないし面倒くさいから
で、対応サンプリングレートが40khzなのに44.1kHzでどうにかなってる理由はよく分かりません!本当は良くないのかも…(笑)
また、RVCではwavファイル以外のmp3など他の拡張子は使えないので注意が必要です。
「上書き回避のためにファイル名を自動ナンバリング」にチェック入れておいた方が便利です。
「◯個のファイルをレンダリング(画像の場合は4個)」を押下してファイルを保存して完了です。
お疲れ様でした!次はこの音声データを学習させる行程に移ります。
ここまで長かったと思いますが、この先はあっという間です!よく頑張りましたーO(∩_∩)O